Advanced Tutorial on Python
Introduction
In this tutorial, we will demonstrate the functionality of the Statescope framework for advanced users:
- Create a custom signature from scRNAseq data
- Use prior expectations for tumor cell fractions, both in single mode (simple model) and group-mode (detailed model, split into Basal/Classical)
- Perform Downstream analysis and interpretation in PDAC application, including retrieval of states in single cell profiles (StateRetrieval)
We will perform deconvolution, refinement and state discovery on the TCGA-PAAD bulk transcriptome dataset of PDAC samples using a custom scRNAseq signature
# Import libraries: All libraries (dependencies) used in this notebook are accompanied with Statescope (installation with pip install Statescope)
import Statescope.Statescope as scope
import pandas as pd
import anndata
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Read TCGA-PAAD dataset, stored locally and retrieved from https://portal.gdc.cancer.gov/projects/TCGA-PAAD
Bulk = pd.read_csv('TCGA_PAAD_Count_Matrix.txt', sep = '\t', index_col = 'gene')
## Normalize bulk to cp10k
Bulk_normalized = Bulk.div(Bulk.sum(axis=0), axis=1) * 1e4
Bulk_normalized.head(3)
We will use a prior for the Tumor cell fractions to increase deconvolution performance. The same ACE (DNA-based) tumor purities, as generated for the manuscript are used.
# Read ACE DNA-based purity estimates
Tumor_purities = pd.read_csv('ACE_Tumor_purities_squaremodel.tsv', sep = '\t', index_col = 'sample')
# Exclude samples with estimated tumor purity of 1
samples_to_exclude = Tumor_purities.index[Tumor_purities['ACE'] == 1].to_list()
# Drop samples to exclude and columns
Tumor_purities = Tumor_purities.drop(samples_to_exclude, axis = 0)
# subset and match Bulk to samples with purity information available
Bulk_normalized = Bulk_normalized[Tumor_purities.index]
print(Tumor_purities)
Read and visualize scRNAseq dataset and annotations
For this tutorial we will use phenotyped scRNAseq data to use as a signature
# Read publicly available, phenotyped scRNAseq dataset from Werba et al
# We have classified Tumor cells into Classical and Basal cells based on the methods from Raghavan et al
scRNAseq_dataset = anndata.read_h5ad('adata_werba.h5ad')
scRNAseq_dataset
# The annotations for the simple model are stored in the major_celltype column and the annotations for the detailed model are stored in the 'subtype' column
print('Simple model celltypes:',scRNAseq_dataset.obs.major_celltype.unique())
print('\nDetailed model celltypes:',scRNAseq_dataset.obs.subtype.unique())
scRNAseq_dataset.obs
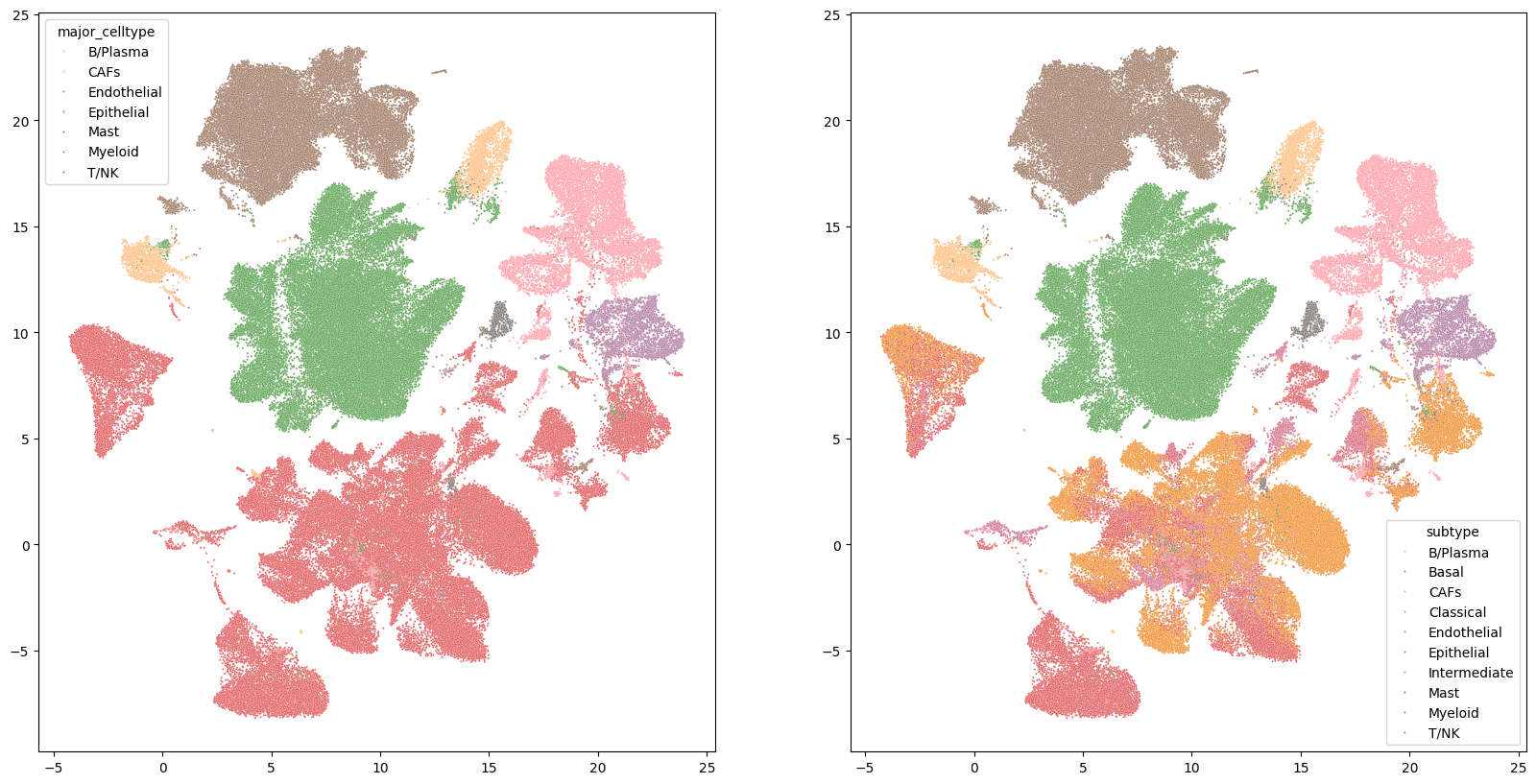
# Visualize annotated UMAP used to create a signature
fig, axes = plt.subplots(1, 2, figsize=(20, 10))
color_pal = {'B/Plasma':'#FFBE7D','CAFs':'#ff9da7','Endothelial':'#B07AA1','Epithelial':'#E15759','Basal':'#E15759','Classical':'#F28E2B','Intermediate':'#D37295','Mast':'#79706E','Myeloid':'#9C755F','T/NK':'#59A14F'}
sns.scatterplot(ax=axes[0], x=scRNAseq_dataset.obsm['X_umap'][:,0], y=scRNAseq_dataset.obsm['X_umap'][:,1], hue = scRNAseq_dataset.obs.major_celltype, s=2, palette = color_pal)
sns.scatterplot(ax=axes[1], x=scRNAseq_dataset.obsm['X_umap'][:,0], y=scRNAseq_dataset.obsm['X_umap'][:,1], hue = scRNAseq_dataset.obs.subtype, s= 2, palette = color_pal)
fig.show()
Statescope initialization
The first step in the Statescope analysis is the initialization of the object. In this notebook we will create two Statescope models, using the different annotations in the scRNAseq dataset ('major_celltype' and 'subtype'). When passing the annotated scRNAseq data to Statescope, a custom deconvolution signature is created with the cell types specified in the celtype_key as follows:
- The scRNAseq count data is validated (has to be library-size corrected and log-transformed)
- The signature is created
- The expected gene expression variability is corrected for highly expressed genes
- Marker genes are detected using the AutoGeneS algorithm
# First lets check the format of adata.X
# Check if adata.X is in log, library-size corrected scaled
scRNAseq_dataset.X # The counts seems to be scaled
Now we will intialize the Statescope models and create the signatures using default parameters. The following paramters can be set:
- CorrectVariance (default=True); whether variance of high expressed genes should be corrected
- n_highly_variable (default=3000); number of highly variable genes used for AutoGeneS
- fixed_n_features (default = None); fixed number of AutoGeneS to be returned
- MarkerList (default = None); Custom marker list to be used instead of AutoGeneS
# Initialize simple model
Statescope_simple_model = scope.Initialize_Statescope(Bulk, Signature = scRNAseq_dataset, celltype_key = 'major_celltype')
# Initialize detailed model
Statescope_detailed_model = scope.Initialize_Statescope(Bulk, Signature = scRNAseq_dataset, celltype_key = 'subtype')
After intialization, several keys are added to the Statescope object which can be accessed at any time
print('First 10 markers:',Statescope_simple_model.Markers[0:10]) # Extra genes can also be manually added: model.Markers = model.Markers + ['MARKERNAME1','MARKERNAME2']
print('Celltypes:',Statescope_simple_model.Celltypes)
Statescope deconvolution
The next step in the Statescope analysis is the deconvolution analysis. In this step, the intial optimization of the Statescope deconvolution module is performed. Here only marker genes are used and the cell fractions are estimated. First we will prepare the priors for the tumor fraction
Optional: Preparing the prior tumor fraction for Statescope deconvolution: Single prior
# Prepare the prior expectation for the tumor cell fraction
# A single expectation is a pandas.Dataframe with shape (Nsample x Ncell)
# Only cell types which are non-nan will be used as a prior
Expectation_single = pd.DataFrame(np.nan, index=Statescope_simple_model.Samples, columns=Statescope_simple_model.Celltypes)
# Fill in expected tumor fractions from ABSOLUTE
Expectation_single.loc[:,'Epithelial'] = Tumor_purities.loc[Statescope_simple_model.Samples,'ABSOLUTE Purity']
Expectation_single
Optional: Preparing the prior tumor fraction for Statescope deconvolution: Group prior
A group expectation is passed as a dictionary with two keys:
- 'Expectation' : which is a numpy array identical to the single prior (with a prior given at index 0)
- 'Group' : which is an numpy array specifying with a value of 1 which cell types are in the group ( (Ncell-Ngroups) x Ncell)
# Prepare group Expectation
Expectation_group = dict()
Group_cts = ['Basal','Classical','Intermediate']
Expectation_group['Expectation'] = Expectation_single.to_numpy() # in the first column the expectation of the group is given
# Create Ngroup x Ncell matrix with 0s, add the group row which has to be the same index as in the Expectation (in this case first row)
Groups = pd.DataFrame(0, index = ['Group'] + [ct for ct in Statescope_detailed_model.Celltypes if not ct in Group_cts], columns = Statescope_detailed_model.Celltypes)
Groups.loc['Group',Group_cts] = 1
for ct in Groups.columns:
if ct not in Group_cts:
Groups.loc[ct,ct] = 1
print('Expectation:\n', Expectation_single.rename(columns={"Epithelial": "Group"}))
print('Group:\n',Groups)
# Add to dict
Expectation_group['Group'] = Groups.to_numpy()
Now we will run the Deconvolution with default parameters
The duration of the deconvolution scales with the number of marker genes, samples and cell types. When available, GPU computing is used, which is preferred and significantly increases computation performance
# Run Deconvolution for simple model with single tumor cell prior
Statescope_simple_model.Deconvolution(Expectation = Expectation_single)
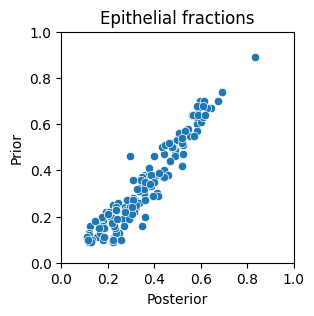
# Lets see if the posterior estimates of the Tumor fractions match the prior expectation
plt.figure(figsize=(3,3))
sns.scatterplot(x=Statescope_simple_model.Fractions.Epithelial, y=Expectation_single.Epithelial)
plt.xlabel('Posterior'); plt.ylabel('Prior')
plt.xlim(0,1); plt.ylim(0,1); plt.title('Epithelial fractions' )
plt.show() # indeed the posterior is highly correlated, but not identical to, the prior
# Run Deconvolution for detailed model with group tumor cell prior
Statescope_detailed_model.Deconvolution(Expectation = Expectation_group)
Statescope Refinement
The next step in the Statescope analysis is the Refinement analysis. In this step, all genes available in the signature are used to performed an additional optimization of the deconvolution. This step is introduced to capture more refined inter-sample variation in the gene expression profiles and is performed for each gene in parralell. The duration of this step decreases with more cores (or less genes) allocated to Statescope (in the intialize step). If only interested in a particular set of genes, a list of genes can be supplied to the 'GeneList' parameter
%%capture
Statescope_simple_model.Refinement()
Statescope State Discovery
The final step in the Statescope analysis is the State Discovery. In this step, the refined cell type-specific gene expression profiles are weighted and subjected to unsupervised clustering analysis using convex-NMF. The output of this module is the StateScores (Sample x K) and StateLoadings (Gene x K) for each cell type. By default, state discovery is performed for each cell type and the number of k is automatically selected based on an heuristic approach.
%%capture
Statescope_simple_model.StateDiscovery()
Evaluate State Discovery: K parameter
It is important to evaluate whether the automatically chosen values for k are sensible. We will create the Cophentic coefficient plot to evaluate the stability of the clustering for the different values of K. As a general rule of thumb, the value of k before the cohpenetic coefficient starts decreasing is the optimal one. It is important to consider that this behaviour can exist at different values of k (multi-modal shape of the plot), and that this approach is less reliable with small sample sizes.
scope.Plot_CopheneticCoefficients(Statescope_simple_model)

The red dot indicates the value of K chosen as the optimal model. For some cell types, the model chosen seems suboptimal, presumably due to the parameters and relatively low sample size. Values for K can be manually adjusted as performed below. For the Eptihelial cell type, four states and for the CAFs five states were chosen, as was done in the manuscript based on better alignment with scRNAseq projections. In this case you could also consider manually adjusting the Endothelial cell type to k=4.
# Example of manually setting K for some cell types
Statescope_simple_model.StateDiscovery(K={'Epithelial': 3,'T/NK': 4})
scope.Plot_CopheneticCoefficients(Statescope_simple_model)

PDAC intratumor heterogeneity
In this notebook we will investigate whether the Epithelial states detected by the simple model correspond to the well defined Basal/Classical subtypes in a completely unsupervised manner. We will relate the findings of the simple model back to see if they correspond to the findings of the detailed model, in which additional prior knowledge (i.e. more supervised) was available.
We will inspect:
- whether the 'Eptithelial' state loadings correspond to well established Classical and Basal markers in literature
- whether 'Epithelial' state scores correspond to the Basal/Classical fractions of the detailed model
- whether 'Epithelial' states retrieved in scRNAseq profiles (StateRetrieval) correspond to Classic/Basal cells
Statescope results and plotting functions
All results of the Statescope analysis are saved within the Statescope model (for example Statescope.Fractions, Statescope.GEX, Statescope.StateScores, Statescope.StateLoadings). In addition, we provide several functions for standard visualization of the results.
1. Investigate whether the 'Eptithelial' state loadings correspond to well established Classical and Basal markers in literature
Here we will inspect the 3 Epithelial states discovered by Statescope by investigating the top loadings. Based on the single-cell analysis of Raghavan et al (2021, Cell), the top 5 markers associated with the Basal subtype (scBasal state) are KRT6A, S100A2, KRT13, KRT17, LY6D and the top 5 markers associated with the Classical subtype (scClassical state) are LGALS4, CTSE, TFF1, AGR2, TSPAN8.
# Inspect top 5 loadings of each Epithelial state
for i in range(len(Statescope_simple_model.StateLoadings['Epithelial'].columns)):
print(f'Top 5 Epithelial State {i+1} markers: ',Statescope_simple_model.StateLoadings['Epithelial'].sort_values(f'Epithelial_{i}',ascending=False).head(5).index)
Top 5 Epithelial State 1 markers: Index(['PNLIP', 'CPA1', 'CPB1', 'PRSS1', 'PRSS2'], dtype='object') Top 5 Epithelial State 2 markers: Index(['KRT17', 'S100A2', 'TGM2', 'KRT7', 'ANXA1'], dtype='object') Top 5 Epithelial State 3 markers: Index(['CHGB', 'TTR', 'CHGA', 'PCSK1N', 'APLP1'], dtype='object') Top 5 Epithelial State 4 markers: Index(['REG4', 'CEACAM5', 'TFF1', 'CLDN18', 'LYZ'], dtype='object')
- The top markers of State 1 seem associated with exocrine/acinar cells
- The top markers of State 2 include keratin genes and S100A2, just like the scBasal State.
- The top markers of State 3 seem associated with endocrine cells
- The top marker of State 4 include TFF1 from the scClassical State and other Classical markers like REG4, CEACAM5 and CLDN18.
2. Investigate whether 'Epithelial' state scores correspond to the Basal/Classical fractions of the detailed model
# We calculate the correlation between Basal/Classical fractions estimated by the detailed model and the Epithelial state scores from the simple model
Corr_matrix = pd.concat([Statescope_detailed_model.Fractions[['Classical','Basal']].apply(lambda x: x / sum(x), axis = 1), Statescope_simple_model.StateScores['Epithelial']], axis = 1).corr()
fig, ax = plt.subplots(figsize=(3, 4))
sns.heatmap(Corr_matrix.loc[Statescope_simple_model.StateScores['Epithelial'].columns,['Basal','Classical']], cmap = 'coolwarm')
fig.show()
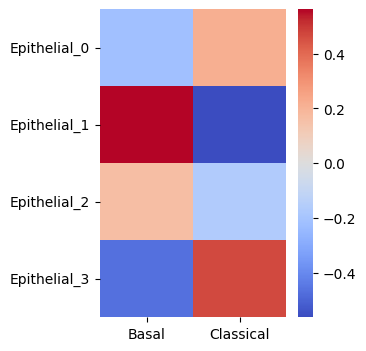
Epithelial state 1 and 3 scores are correlated with the Classical fractions of the detailed model. Epithlial state 2 scores are correlated with the basal fractions in the detailed model.
3. Investigate whether 'Epithelial' states retrieved in scRNAseq profiles (StateRetrieval) correspond to Classic/Basal cells
Here we will make use of the natural property of cNMF to retrieve cell state scores in new cell type-specific gene expression data (scRNAseq) using an existing state loadings matrix. Here we will uncover the intratumor heterogeneity by selecting one PDAC sample in the scRNAseq dataset with both basal and classical cells.
scRNAseq_dataset.obs
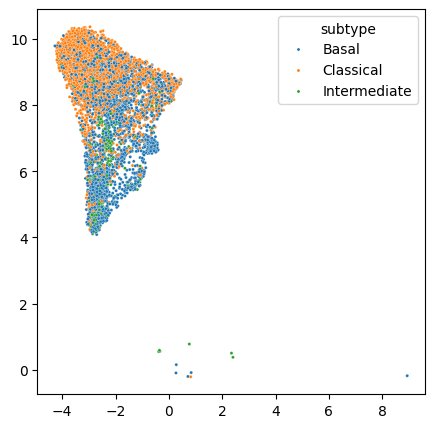
Lets select the cells of one tumor for state retrieval
fig, ax = plt.subplots(figsize=(5, 5))
scRNAseq_dataset.obs['patient'] = [x.split(':')[0] for x in scRNAseq_dataset.obs.index]
scRNAseq_subset = scRNAseq_dataset[((scRNAseq_dataset.obs.patient == 'Nov-6115-d0') & (scRNAseq_dataset.obs.major_celltype == 'Epithelial'))]
sns.scatterplot(ax=ax, x=scRNAseq_subset.obsm['X_umap'][:,0], y=scRNAseq_subset.obsm['X_umap'][:,1], hue = scRNAseq_subset.obs.subtype, s=5)
fig.show()
State Retrieval
We will retrieve the Epithelial states detected from the bulk samples in single Epithelial cell profiles from one tumor
GEX = pd.DataFrame(scRNAseq_subset.X.toarray(), index = scRNAseq_subset.obs.index, columns = scRNAseq_subset.var.index)
StateScores_scRNAseq = scope.StateRetrieval(GEX = GEX, Omega = Statescope_simple_model.scVar[['scVar_Epithelial']].rename(columns = {'scVar_Epithelial':'Epithelial'}), celltype='Epithelial', StateLoadings = Statescope_simple_model.StateLoadings['Epithelial'])
StateScores_scRNAseq
fig, axes = plt.subplots(1,len(StateScores_scRNAseq.columns)+1,figsize=(25, 5))
axes = axes.ravel()
sns.scatterplot(ax=axes[0], x=scRNAseq_subset.obsm['X_umap'][:,0], y=scRNAseq_subset.obsm['X_umap'][:,1], hue = scRNAseq_subset.obs.subtype, s=5)
for i in range(len(StateScores_scRNAseq.columns)):
sns.scatterplot(ax=axes[i+1], x=scRNAseq_subset.obsm['X_umap'][:,0], y=scRNAseq_subset.obsm['X_umap'][:,1], hue = StateScores_scRNAseq[i], s=5,palette='viridis', legend = False)
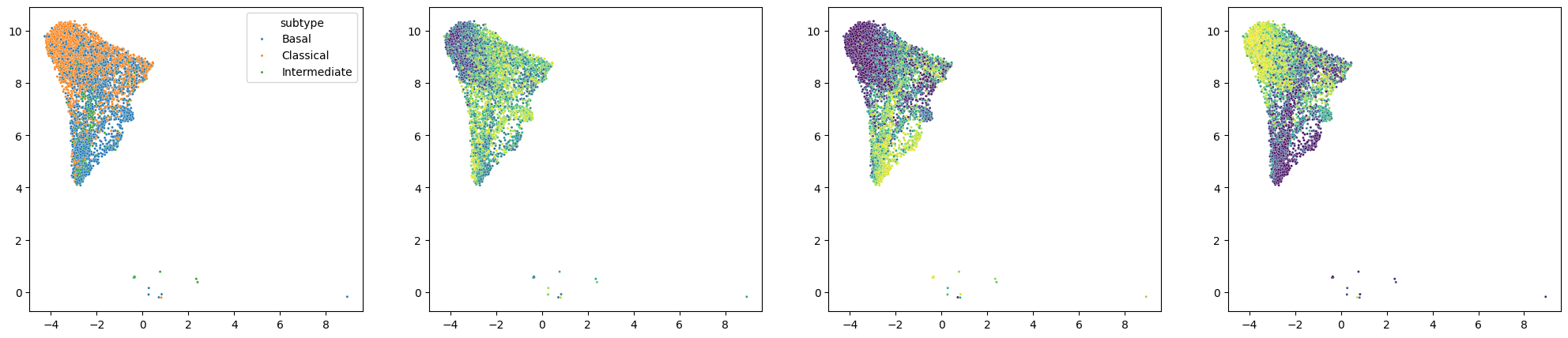
Here we observe an enrichment of State 3 scores in the classical cells and an enrichment of State 2 scores in the basal cells.
Taken together, Statescope identified Epithelial state 2 as Basal and Epithelial state 3 as Classical.
Saving, Loading, and CPU/GPU Interoperability
Statescope models are not fully portable when using pickle.load. Use the built-in Statescope.load() and model.save() helpers for CPU/GPU interoperability.
Example:
model = Statescope.load(
"/net/beegfs/users/P094398/StatescopeBenchmark/Benchmark/Data/Alldone.pkl",
device="cpu",
)
model.StateDiscovery()
model.EcotypeDiscovery()
# Save the model; if you ran on GPU, you can save it for CPU use like this
model.save(
"/net/beegfs/users/P094398/Deployed_Dec/tutorial/Output/AllFinal_PBMC5.pkl",
to_cpu=True,
)
Notes:
- Use
device="cpu"when opening on CPU, anddevice="cuda"when opening on GPU. - It is recommended to save your model after each module (e.g., after deconvolution, refinement, and state discovery).